Ming-UniAudio - 蚂蚁开源的统一音频多模态生成模型
Ming-UniAudio是蚂蚁集团开源的统一音频多模态生成模型,支持文本、音频、图像和视频的混合输入与输出。采用多尺度Transformer和混合专家(MoE)架构,通过模态感知路由机制高效处理跨模态信息,显著提升计算效率。模型在语音合成、声纹克隆、多方言生成及音频-文本跨模态任务上表现优异,同时具备高质量实时生成能力。开源特性为研究社区提供了可扩展的解决方案,推动多模态技术发展与实际应用创新。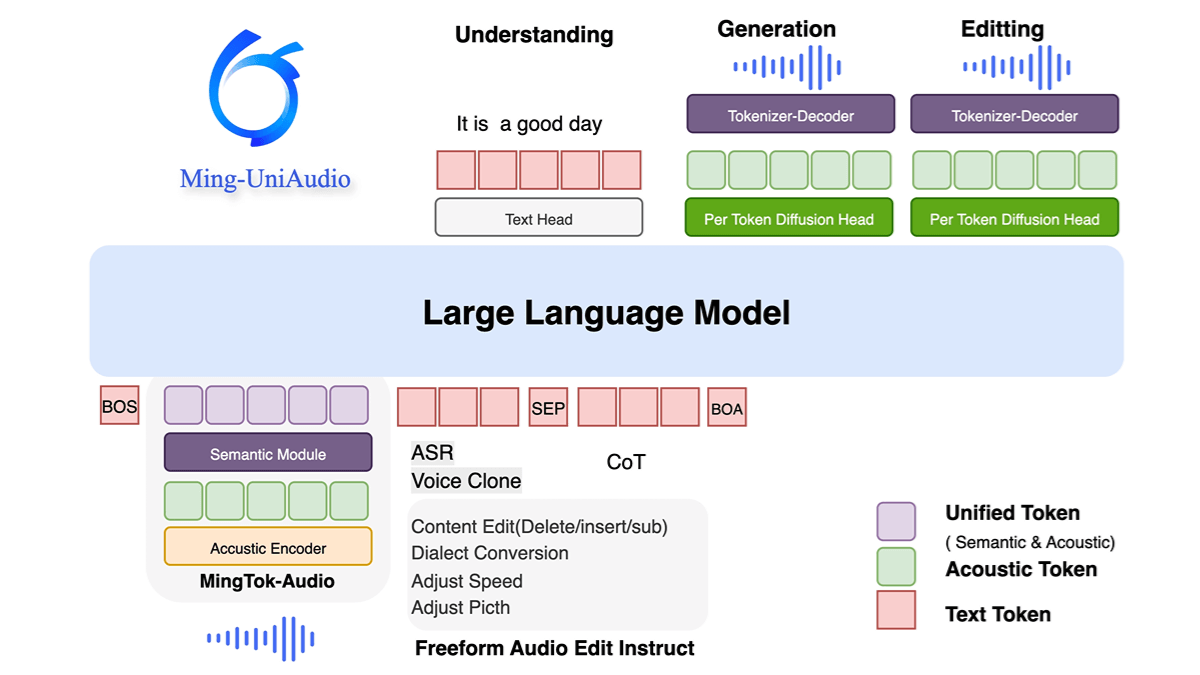
Ming-UniAudio是蚂蚁集团开源的统一音频多模态生成模型,支持文本、音频、图像和视频的混合输入与输出。采用多尺度Transformer和混合专家(MoE)架构,通过模态感知路由机制高效处理跨模态信息,显著提升计算效率。模型在语音合成、声纹克隆、多方言生成及音频-文本跨模态任务上表现优异,同时具备高质量实时生成能力。开源特性为研究社区提供了可扩展的解决方案,推动多模态技术发展与实际应用创新。