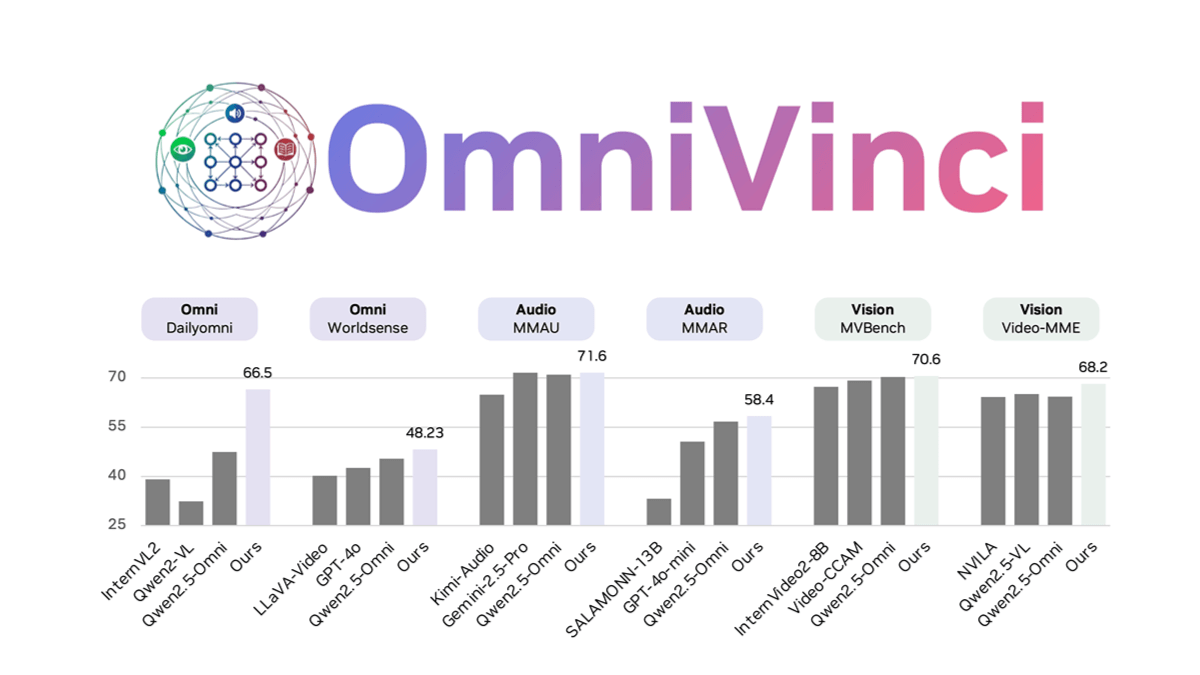
OmniVinci 是 NVIDIA 开发的开源全模态大型语言模型,通过架构革新和数据优化解决多模态模型中的模态割裂问题。通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉相对时间对齐信息,采用约束旋转时间嵌入编码绝对时间信息。OmniVinci 通过数据合成和精心设计的数据分布策略,生成大量单模态和全模态对话样本进行训练。两阶段训练策略先进行单模态训练,再进行全模态联合训练,有效整合多模态理解能力。OmniVinci 在多个基准测试中表现优异,如在 DailyOmni 上评分比 Qwen2.5-Omni 高出 19.05 分,且训练标记量大幅减少。已应用于医疗 CT 影像解读、半导体器件检测等领域,展现出强大的多模态理解能力。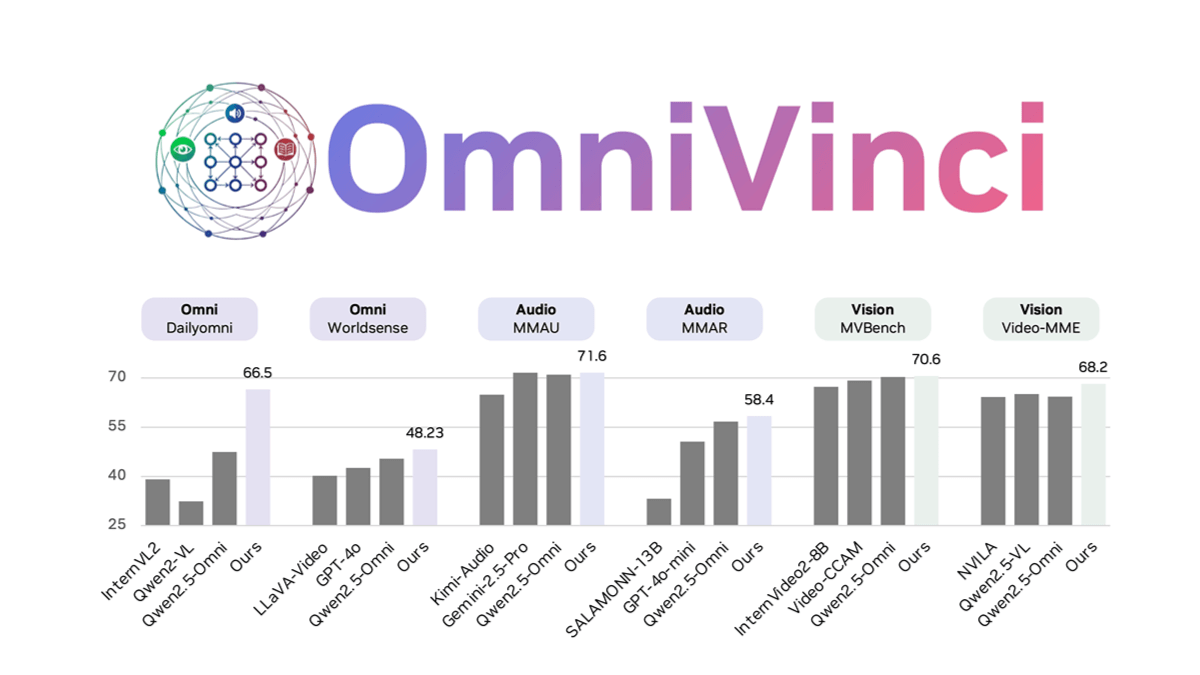
>>展开阅读
喜欢桌面美化的小伙伴又可以折腾了,一款支持批量替换软件快捷方式图标进行美化的开源工具「LinkEcho」对比传统的手动替换方式,这个软件支持一键载入开始菜单图标或者桌面图标,然后进行图标替换美化,还支持自定义图标设计。
>>展开阅读
Dexbotic是原力灵机(Dexmal)开源的具身智能视觉-语言-动作(VLA)模型一站式科研服务平台,解决具身智能领域研究碎片化、效率低等问题。以 PyTorch 为基础,为具身智能领域的研究和开发提供了一站式的解决方案。Dexbotic 的核心优势在于其统一的模块化框架,能兼容多种主流大语言模型接口,集成具身操作与导航模块,并预留了扩展能力,为未来更复杂的任务场景提供了架构基础。提供了高性能的预训练基础模型,针对多种主流算法进行了优化,显著提升了在仿真和真实任务中的表现。Dexbotic 支持云端和本地一体化训练,适配多种研发环境,提供了全链路的机器人训练与部署支持,覆盖从仿真验证到真实机器人落地的完整流程。
>>展开阅读
ValueCell是开源的多智能体金融应用平台,通过AI技术提升金融分析和投资管理的效率。模拟专业投资团队,多个AI智能体分工协作,涵盖市场分析、情绪分析、基本面研究、自动交易等功能,为用户提供全面的金融洞察。支持OpenAI、OpenRouter等多种大语言模型,覆盖美股、A股、加密货币等多市场数据,兼容LangChain等主流AI框架。提供深度研究报告、自动交易策略、实时市场数据推送,以及基于知名投资大师理念的智能体(如巴菲特、芒格风格),帮助用户优化投资组合。
>>展开阅读
olmOCR 2是Allen Institute for Artificial Intelligence(AI2)开源的多模态文档解析模型,是olmOCR的升级版本。将数字化的打印文档(如 PDF)高效转换为干净、自然排序的纯文本。基于Qwen2.5-VL-7B模型,通过强化学习(RLVR)优化,结合合成数据生成与单元测试机制,解决传统OCR在复杂场景(如数学公式、表格、多列布局)中的精度问题。在文档解析任务中表现突出,尤其在处理复杂格式和结构化内容时,准确率显著高于同类模型。例如,在数学公式识别、表格数据提取等任务中,能更精准地还原文档内容。
>>展开阅读
有 NAS 或者服务器的小伙伴可以在 Docker 里面安装微信或者 QQ 了,给大家分享这个「WeChat Selkies」项目,据介绍通过 Selkies 的 WebRCD 技术把界面投送到 Web 浏览器,无需在本地安装微信/QQ 客户端,适用于服务器部署、远程办公等场景。
>>展开阅读
LongCat-Video是美团LongCat团队开源的13.6亿参数视频生成模型,采用MIT开源协议,支持文生视频、图生视频和视频续写三大任务。模型通过"粗到细"生成策略和块稀疏注意力机制,能在数分钟内生成720P高清长视频,保持色彩一致性且无质量衰减。技术亮点包括多奖励强化学习优化,性能接近商业级SOTA模型,在内部测试中多项指标超越同类开源模型。模型已在Hugging Face和GitHub开源,提供文本/图像输入、视频续写等一键式部署方案。
>>展开阅读
开源轻量级个人导航站「MeNav」高度可定制,让您轻松创建属于自己的导航主页。无需数据库和后端服务,完全静态部署。支持一键 Fork 部署到 GitHub Pages,还可以从浏览器书签一键导入网站。配合 MarksVault 浏览器扩展,更支持书签自动同步和导航站自动更新。
>>展开阅读
- «
- 1
- ...
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- ...
- 116
- »